
Ubuntuを使っていて「なんだか最近重い…」と感じた経験はありませんか?
原因が分からず、とりあえず再起動してしまうこともあるかもしれません。けれど、リソースのどこに負荷がかかっているかを確認するだけで、思いのほかスムーズに原因を絞り込めるようになります。
本記事では、私の経験をふまえながら、Ubuntuで「重い」と感じたときに真っ先に確認すべきポイントと、役立つコマンドの使い方を紹介します。

重いから再起動をする・・前に、ぜひご一読ください
この記事を読むとわかること
- Ubuntuで高負荷の原因をコマンドで特定する方法
- CPU・メモリ・ディスク・ネットワーク各リソースの負荷チェック手順
- 再起動せずに問題を切り分けるための調査フロー
Ubuntuが重たくなったとき、最初に見るべきリソースとは?
Ubuntuで動作が重くなったとき、原因を探るには「どのリソースが逼迫しているのか」を冷静に確認する必要があります。
CPU、メモリ、ディスク、ネットワークのどこに負荷がかかっているかで対処法は大きく変わるため、やみくもに再起動するのではなく、まず状態を観察するのが第一歩です。
とはいえ、初学者にとっては「何を見れば“重い”と言えるのか」が分かりづらいかもしれません。
私も最初は動作が重くなるたびに「とりあえず再起動」でごまかしたことが何度かありました。けれど、基本的なコマンドを押さえておけば、具体的な手がかりが見えてくるようになります。
「高負荷」とは何か?各リソースの逼迫サインを理解しよう
「高負荷」とは単純にCPUが100%で動いている状態だけではありません。CPU、メモリ、ディスクI/O、ネットワーク…それぞれのリソースに過剰なアクセスや使用が発生していることを指します。
例えば、バックグラウンドで大量のファイル転送が起きていればディスクI/Oが原因かもしれませんし、何かのプロセスが暴走してメモリを使い切っていればスワップが大量に発生している可能性があります。このように、「重い」の中身を細かく分解して捉える視点が大切です。
また、急な高負荷の前には小さな兆候が出ていることが多く、定期的に負荷の状況を観察する習慣があると「おかしい」と気づくタイミングが早くなります。
再起動する前に確認すべきリソース情報と理由
動作が重くなるとつい再起動したくなりますが、その前に必ずやっておきたいのが現状の把握です。uptimeやtop、freeなどで今のリソース状況を記録しておけば、次に同じようなことが起きたときに状況を比較でき、真因を特定することができます。
ちょっと面倒でも、数コマンドだけでも先に確認しておくと、後々役に立つ場面が出てきます。
私の体験談ですが、あるときVPSが重くなったので「再起動すれば治るだろう」と安易に再起動してしまいました。
たしかに一時的には軽くなったのですが、翌日また同じ症状が発生。調べてみると、ログには OOM Killer の記録が残っており、メモリ不足で重要なプロセスが落ちていたことが分かりました。
もし最初の段階で free -h や journalctl を確認していれば、サービス停止を未然に防げたはずです。
以降は、再起動前に状況を把握するクセが身につきました。
top/htopで“犯人プロセス”を見抜く方法【CPU編】
Ubuntuで高負荷の原因を特定するとき、最初に見ておきたいのがCPUの状態とそれを使っているプロセスです。topとhtopは、その代表的なコマンドになります。topは標準搭載で軽量、htopは見やすさが特長です。
load average の見方:過負荷を数値で見抜く指標とは?
topを開くと、画面上部に「load average」という数字があります。
これはCPUの混雑具合を示すもので、直近1分・5分・15分の平均負荷を表示しています。
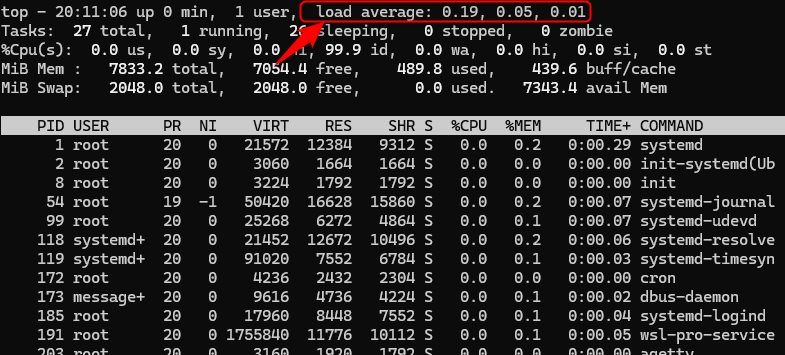
この値が「CPUのコア数」より常に高くなっていると、処理待ちが発生している可能性が高いです。たとえば2コアのマシンで「load average: 4.0」なら、明らかに過負荷です。
CPU使用率の高いプロセスを特定して問題を切り分ける
次に、どのプロセスがCPUを食っているかを確認します。topコマンドを実行すると、%CPUの欄に注目することで負荷の高いプロセスが分かります。

ここでCPU使用率が高いプロセスを見つけたら、対象のサービスやスクリプトが暴走していないかを疑ってみます。Web系のサーバーでは、PHPやApacheが原因になっていることもよくあります。
htopで一目で分かる負荷状況:見方と操作のコツ
htopはインストールが必要ですが、見やすさと操作性が抜群です。色分けされたCPU使用率や、ソートの切り替えが矢印キーでできるので、topよりも直感的に把握できます。
sudo apt install htop
htop実際に使ってみると、リソースがどこに集中しているかが一目で分かるようになります。特にマルチコアCPUの動きや、メモリ・スワップの使用状況をぱっと見でつかめるのがありがたいです。
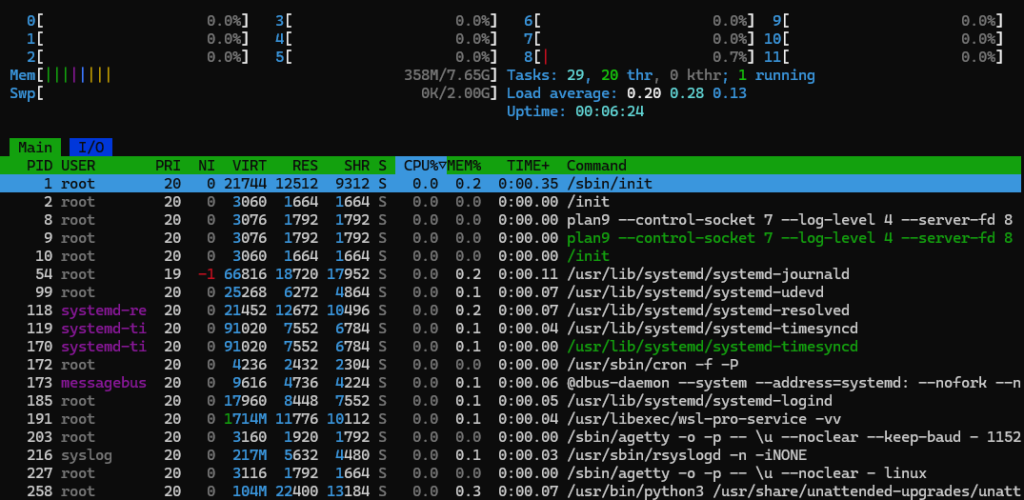
メモリ不足の兆候とスワップ使用が教えてくれること
CPUだけでなく、メモリが足りないことで動作が重くなるケースも非常に多いです。メモリが逼迫するとスワップ領域が使われ始め、ディスクアクセスが頻繁になって応答が遅くなります。
free / vmstat の使い方:メモリとスワップ状況を即確認
メモリの状況を見る基本コマンドはfree -hです。availableの値が少なく、swapの使用量が増えていたら注意です。
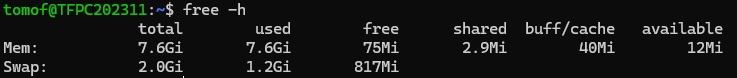
| 項目 | 値 | 解説 |
|---|---|---|
Mem: used | 7.6Gi(全体の100%) | メモリが完全に使い切られている状態 |
available | 12Mi | ほぼゼロ。新たな処理に使える余裕がない |
swap used | 1.2Gi | 明確にスワップ使用が始まっている(約60%消費中) |
buff/cache | 40Mi | キャッシュ領域すら解放されてしまっている |
さらに詳細を見たいときはvmstat 1で1秒ごとのメモリやI/Oの動きを観察できます。si(swap in)とso(swap out)が活発なら、メモリが足りていないサインです。
プロセス強制終了の犯人「OOM Killer」の痕跡を探す方法
メモリ不足が深刻になると、カーネルが自動的にプロセスを終了させる「OOM Killer(Out of Memory Killer)」が動きます。これが発生していないか、dmesgやjournalctlで確認できます。
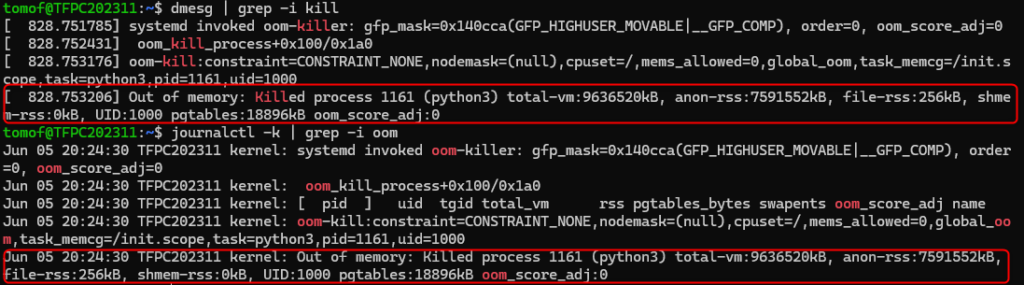
| コマンド | 特長 | 使いやすさ | ログの範囲 | 向いている場面 |
|---|---|---|---|---|
dmesg | カーネルリングバッファを直接表示 | 高速・軽量 | 起動後の最新メッセージのみ(古いログは消える) | 瞬時のエラー確認、障害直後の調査など |
journalctl -k | systemdのジャーナル経由でカーネルログを見る | フィルタ・時系列・永続性あり | 長期的なカーネルログも含まれる(保持設定による) | 過去の障害履歴を追う、時間指定で分析 |
※カーネルリングバッファ:Linuxカーネルが起動してから今までのあいだに出力した「メッセージの一時保管場所」
知らないうちに大事なプロセスが落ちていた…なんてこともあるので、スワップが増えたときはこの確認も忘れずに。
ディスクI/Oが原因?遅いときに確認すべき指標とコマンド
意外と見落とされがちなのがディスクI/Oの問題です。読み書きの待ち時間が長いと、CPUは暇でもシステム全体が重く感じられます。
iostatでI/O待ち時間(iowait)を見抜く方法
iostatを使うと、CPUがI/O待ちにどれくらい時間を使っているか(iowait)を確認できます。まずはsysstatをインストールしましょう。
sudo apt install sysstat
iostat -x 1 3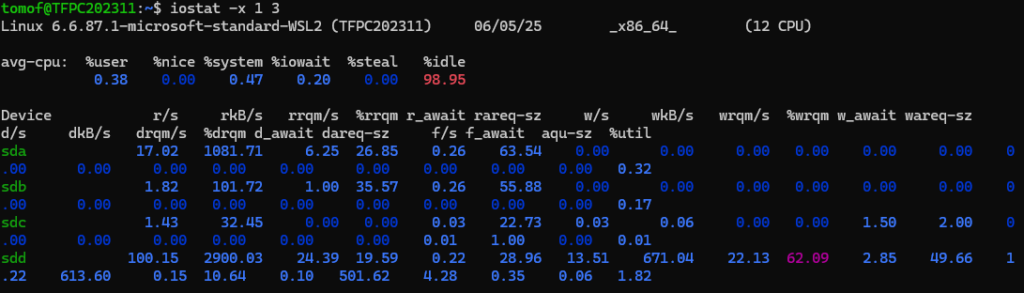
出力にある%iowaitが10%を超えているようなら、ディスクがボトルネックになっている可能性が高いです。
iotopでディスクを圧迫しているプロセスを特定する方法
iotopはディスクI/Oを多く発生させているプロセスをリアルタイムで表示するコマンドです。root権限で実行します。
sudo apt install iotop
sudo iotop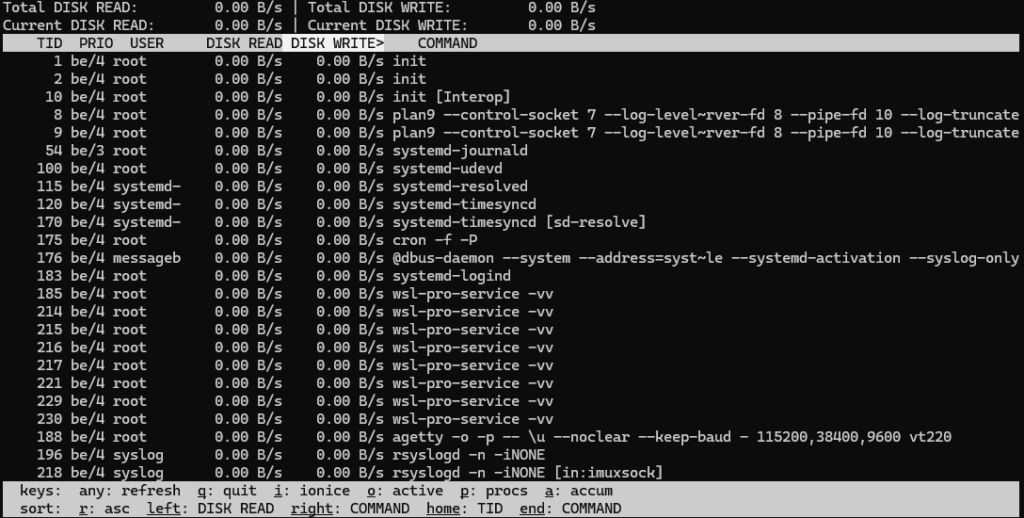
ここで書き込みや読み込みが激しいプロセスが見つかれば、それが原因かもしれません。バックアップやログ書き出し処理が暴走していることもあります。
意外な落とし穴:ネットワーク負荷が重さの原因かも?
CPUやディスクは問題ないのに遅い…そんなときはネットワークが原因になっていることも。特に家庭内サーバーでは、外部からの過剰なアクセスに気づきにくいです。
iftopで“帯域泥棒”を見つける方法:重い原因が通信にある場合
iftopを使うと、どのIPとどれだけ通信しているかが視覚的に分かります。インストールが必要ですが、見やすさは抜群です。
sudo apt install iftop
sudo iftopどこかのIPと大量の通信が行われていれば、それが高負荷の原因かもしれません。IPを控えて、アクセス元を調べてみましょう。
帯域専有や不審なアクセスをどう見つけるか?調査ポイントまとめ
たとえば、動画配信やファイル共有サービスが帯域を専有していたり、外部からポートスキャンを受けていたりすることがあります。こうした「想定外の通信」がないか、iftopやnetstatで観察することが重要です。
ログに残されたヒントで“高負荷の真因”を特定する
リソースの状態だけでなく、システムログには異常のヒントが隠れていることがよくあります。特に、サービスが落ちていたり、I/Oエラーが起きていたりする場合はログが重要です。
journalctlを活用して異常のタイミングをピンポイントで確認
journalctlはログを時系列で追えるコマンドです。重くなった時間帯が分かっている場合は、時間を絞って確認できます。
journalctl --since "10 minutes ago"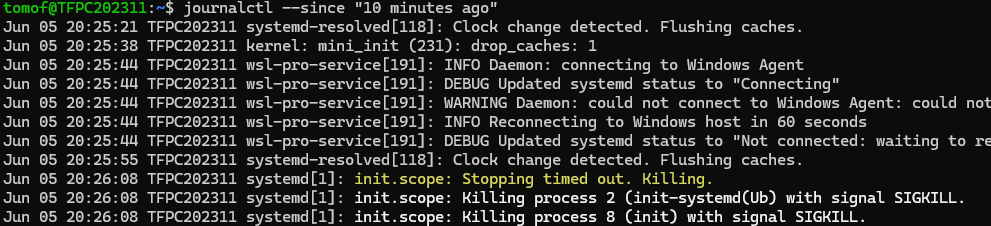
このように時間帯を区切ることで、問題が起きた直前のログを効率よく見つけられます。
サービス停止・I/Oエラーの兆候をログから見つけるには
ログ内に「Failed」や「I/O error」などが出ていれば、明らかなトラブルです。対象のサービス名も一緒に表示されていれば、再起動や調査の手がかりになります。
高負荷時の調査フロー(コマンドと解説付き)
最後に、初心者が高負荷のときに何から見ればいいか、シンプルな調査フローを紹介します。慣れてくれば自然と体で覚えられますが、最初はこの順番を意識するだけでも随分と違います。
#!/bin/bash
# -------------------------------
# 1. システム全体の平均負荷を確認
# 1分・5分・15分の load average を表示
# CPUコア数を超える値が続いていれば、過負荷の兆候
uptime
# -------------------------------
# 2. topでCPU・メモリの負荷を確認
# %CPUの高いプロセスがないか確認(top起動後にPキーでソート可能)
# 状況だけ見るなら1回だけ出力する(-n 1)
top -n 1
# -------------------------------
# 3. htopでリソース使用状況を視覚的に確認(必要に応じて Ctrl+C で終了)
# CPUごとの使用率や、メモリ・スワップの使用状態を視覚的にチェック
# プロセスの並び替えやkill操作も可能(要インストール)
htop
# -------------------------------
# 4. freeでメモリとスワップの使用状況を確認
# availableが極端に少なく、swapの使用量が増えていればメモリ不足の兆候
free -h
# -------------------------------
# 5. vmstatでメモリ・I/Oの動きを確認
# si(swap in)、so(swap out)の値が頻繁に増えていればスワップ使用中
vmstat 1 5
# -------------------------------
# 6. iostatでディスクI/O待ち時間を確認(要 sysstat)
# %iowaitが10%以上ある場合は、ディスクI/Oがボトルネックの可能性
iostat -x 1 3
# -------------------------------
# 7. iotopでディスクを激しく使っているプロセスを確認(要 root)
# 実行時に表示される「DISK READ」「DISK WRITE」をチェック
# 高負荷をかけているプロセスが上位に表示される
sudo iotop -obn3
# -------------------------------
# 8. iftopでネットワークの通信状況を確認(要 root)
# 送受信が多いIPアドレスを表示。帯域を専有している通信を特定
# qキーで終了
sudo iftop -t -s 10
# -------------------------------
# 9. journalctlでログから異常を探す
# OOM Killerの発動履歴や、サービス・ハードウェアの異常を確認
# 'oom', 'fail', 'error' などで絞り込み
journalctl -k | grep -Ei "oom|fail|error"
この順番で見ていけば、「とりあえず再起動」から一歩進んで、「何が起きていたのか」を把握できるようになります。
まとめ
Ubuntuが重く感じられるとき、その原因はCPUやメモリだけでなく、ディスクやネットワークにも潜んでいます。
本記事で紹介した調査の手順を習慣づけておけば、ただの再起動では得られなかった「何が問題だったのか」の手がかりがつかめるようになります。
私自身、このチェックフローを覚えてからは、トラブル時に焦らず対応できるようになりました。もちろん環境によって最適な対応は異なるので、これをベースに自分なりの観察方法を育てていくのもおすすめです。
セキュリティ対策も忘れずに
Ubuntuの運用では「重くなった原因を特定する」ことも大切ですが、それ以前に「トラブルを未然に防ぐ環境構築」も重要です。
初期構築時に最低限やっておきたいセキュリティ設定については、以下の記事で詳しく紹介しています:



